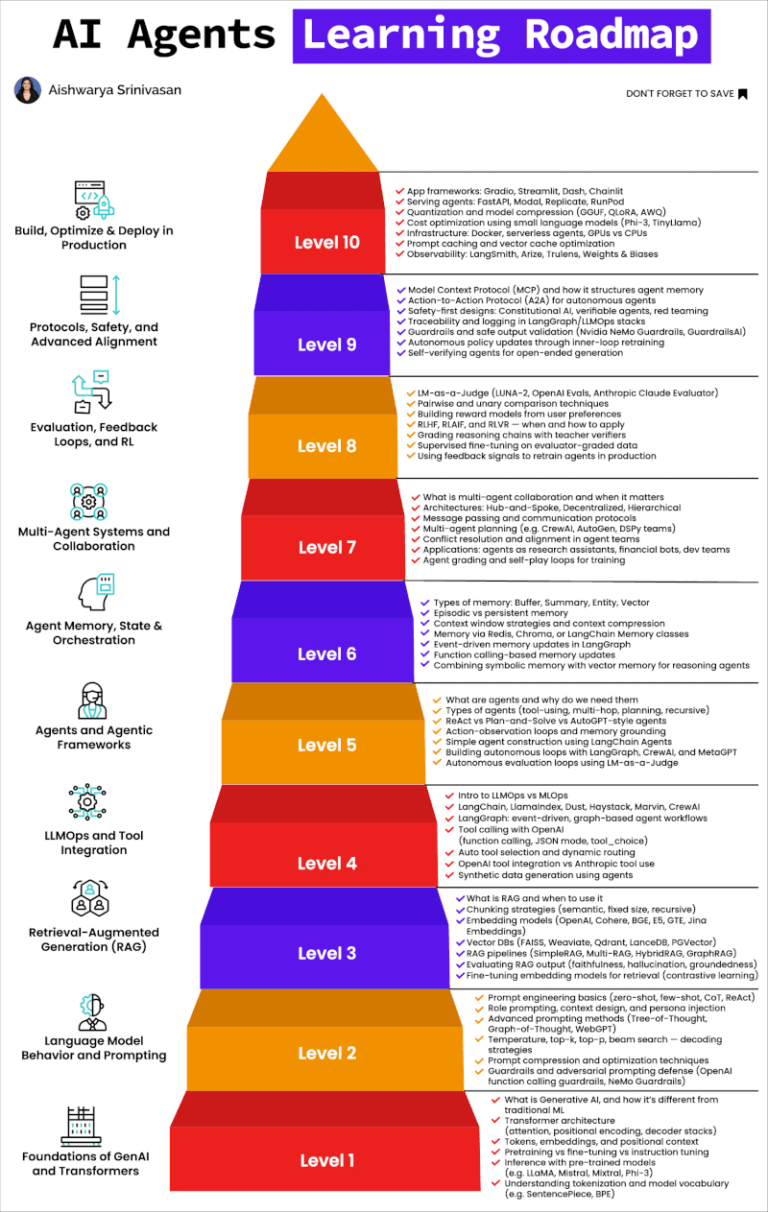
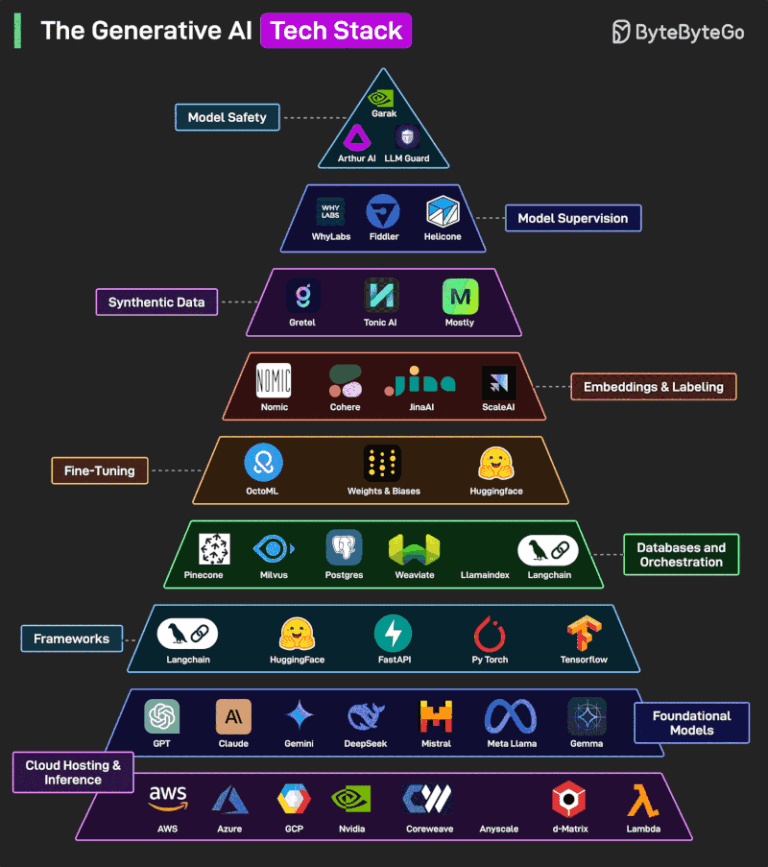
Resume Auto-Rewriter Pipeline: Personalized Resumes, Instantly
The Resume Auto-Rewriter is a fully automated, stateless system that tailors resumes to match specific job descriptions—all triggered by a simple email.
How it works:
- Email Trigger
Registered members of the AABA send a job description in the content of an email, to the addressresume_rreck@aab-ai.org. The system captures the sender’s email and the job posting from the email’s content. - Processing Begins
A Procmail rule launches the pipeline. A unique working directory is created based on the current UNIX timestamp, isolating the session. - Input Handling
- The job description is stored as
job_req.txt - The sender’s email is saved as
sender.txt
- The job description is stored as
- Reference Materials
- A master resume (
resume.txt, markdown) is used as the base - A transformation prompt (
resume_prompt.txt) guides the rewriting process
- A master resume (
- LLM-Powered Rewrite
A Large Language Model processes the resume and job description to generate a tailored markdown version, saved asresponse.txt. - PDF Generation
The response is converted to a professionally styled PDF using Pandoc and custom Latex. - Delivery
The new resume is emailed back to the sender, with the PDF attached. Each invocation is logged for traceability.
Key Features:
- Stateless and reproducible
- Human-readable audit trail per run
- Easy to extend and debug
- Outputs clean, professional resumes in PDF format
This pipeline brings precision, personalization, and automation to resume tailoring—powered by AI, with zero friction.
- Email Received: An email is sent to
resume_rreck@aab-ai.org. The body contains a job description. The sender’s address is extracted. - Procmail Triggered: A
procmailrule is triggered, invoking a shell script (e.g.,resume_handler.sh). - Working Directory Created: The script creates a directory using the current UNIX timestamp (e.g.,
~/1711902342/). This becomes the isolated workspace for that invocation. - Input Captured:
- The job description is saved as
~/<EPOCH>/job_req.txt - The sender’s address is saved as
~/<EPOCH>/sender.txt
- The job description is saved as
- Static Files Referenced:
- The resume to be adapted is loaded from
~/resume.txt(already in markdown format) - The transformation prompt is read from
~/resume_prompt.txt
- The resume to be adapted is loaded from
- Chat Completions API Called:
- The script constructs a JSON payload using:
systemmessage: contents ofresume_prompt.txtusermessage: contents ofjob_req.txt
- The request is sent via
curlto the OpenAI API - The resume (
resume.txt) is included inline in the prompt if needed
- The script constructs a JSON payload using:
- Output Stored:
- The LLM’s response (in markdown format) is saved to
~/<EPOCH>/response.txt
- The LLM’s response (in markdown format) is saved to
- PDF Generation:
- The markdown response is processed with pandoc using a stylesheet
- Command:
pandoc ~/<EPOCH>/response.txt -o ~/<EPOCH>/resume.pdf --css ~/simple.css - The resulting PDF is saved in the working directory
- Email Sent:
- The generated PDF is attached to an email sent back to the sender using the address stored in
sender.txt - The directory serves as an audit trail for every run
- The generated PDF is attached to an email sent back to the sender using the address stored in
This pipeline is entirely stateless, reproducible, debuggable, and extensible. Each user’s resume lives at a fixed path, each job request is captured in isolation, and the tailored resume is returned in professional PDF format.